分桶的工作原理
分桶的工作原理
概述分桶如何将用户分配到功能推出或云眼灰度标帜(Feature Flag)AB实验的实验。
📘 高深
如果是实验的高级用户,则此详细主题适合您。如果主要使用标帜传递,则本主题不那么相关。
分桶是根据标帜规则将用户分配到标帜变体的过程。云眼灰度标帜(Feature Flag)AB实验 SDK 评估用户 ID 和属性,以确定他们应该看到的变体。
分桶是:
- 确定性:用户每次看到实验时,都会在他们使用的所有设备上看到相同的变体,这要归功于我们对用户 ID 进行哈希处理的方式。换句话说,返回的用户不会重新分配给新的变体。
- 除非重新配置,否则粘滞:如果重新配置“实时”运行标帜规则(例如_,_通过减少然后增加流量),则用户可能会被重新分类到不同的变体中。
如何对用户进行分桶处理
在分桶期间,SDK 依靠 MurmurHash函数将用户 ID 和实验 ID 哈希为映射到分桶范围的整数,该整数表示变体。MurmurHash是确定性的,因此只要实验条件不变,用户ID将始终映射到相同的变体。这也意味着,只要用户 ID 和用户属性在系统之间一致共享,任何 SDK 都将始终输出相同的变体。
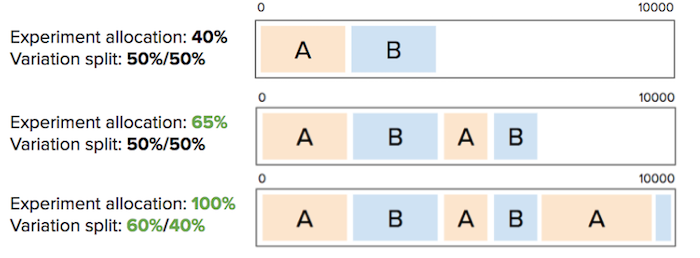
例如,假设正在运行一个包含两个变体(A 和 B)的实验,实验流量分配为 40%,两个变体之间的分布为 50/50。云眼 将为每个用户分配一个介于 0 和 10000 之间的数字,以确定他们是否符合实验条件,如果是,他们将看到哪些变体。如果他们在分桶 0 到 1999 中,他们会看到变体 A;如果它们位于分桶 2000 到 3999 中,则会看到变体 B。如果他们在分桶 4000 到 10000 中,他们根本不会参与实验。这些分桶范围是确定性的:如果用户落在分桶 1083 中,他们将始终位于分桶 1083 中。
此操作非常高效,因为它发生在内存中,并且无需阻止对外部服务的请求。它还允许跨渠道和多种语言进行分桶,以及在没有强大网络连接的情况下进行实验。
另请参阅标帜规则之间的交互。
更改流量可以重新分桶用户
更改已启用灰度标帜(Feature Flag)的“实时”流量的最常见方法是增加流量。在此方案中,可以单调地增加总体流量,而无需重新划分用户代码。
但是,如果以非单调方式更改流量(例如,减少流量,然后增加流量),则用户可能会重新存储。在理想情况下,可以避免对正在运行的实验进行非流量更改,因为这可能会导致指标在统计上无效。一个例外是,如果使用的是我们的统计加速器(通常作为成熟的渐进式交付文化的一部分)。如果使用的是统计信息加速器,或者需要更改“实时”实验流量,则可以通过实施用户配置文件服务来确保用户变体分配具有粘性。有关详细信息,请参阅用户配置文件服务。用户配置文件服务与实验兼容,与标帜传递不兼容。
| 重新配置传递流量 | 用户是否会被重新存储? |
|---|---|
| 单调增加整体流量 | 否 不会重新存储现有用户。 |
| 非单调地更改流量 | 是 例如,如果从 80% 的受众开始,然后将流量减少到 50%,然后又增加到 80%,则当您再次增加百分比时,以前看到该标帜的用户可能不再看到该标帜。但是,如果在不更改流量的情况下打开和关闭投放,则相同的用户会看到该标帜。 |
| 重新配置实验流量 | 用户是否会被重新分类? |
|---|---|
| 单调增加整体流量分配 | 不 |
| 暂停实验中的变体(通过将变体的流量设置为 0%) | 是 在可能的情况下,云眼保留现有分桶 |
| 非单调地更改整体流量分配 | 是 在可能的情况下,云眼保留现有分桶 |
| 更改变体之间的流量分配或添加/删除变体 | 是 在可能的情况下,云眼保留现有分桶 |
| 重新配置互斥实验组 | 用户是否会被重新分类? |
|---|---|
| 单调地增加每个实验的总体流量分配 | 不 |
| 暂停/播放组中的实验 | 不 |
| 非单调地更改每个实验的总体流量分配 | 是 在可能的情况下,云眼保留现有分桶 |
| 更改实验之间的流量分布或在互斥组中添加/移除实验 | 是 在可能的情况下,云眼保留现有分桶 |
若要避免重新加载,请实现用户配置文件服务。用户配置文件服务与转出不兼容。
重新分桶示例
让我们看一个详细示例,说明 云眼 在重新配置正在运行的实验时如何尝试保留分桶。
假设正在运行一个包含两个变体(A 和 B)的实验,实验总流量分配为 40%,两个变体之间的分布为 50/50。在此示例中,如果将实验分配更改为除 0% 以外的任何百分比,云眼 可确保尽可能保留所有变体分桶范围,以确保用户不会被重新归入其他变体。如果添加变体并增加整体流量,云眼 将尝试将新用户放入新版本中,而无需重新存储现有用户。
继续该示例,如果将变体流量从 40% 更改为 0%,云眼 将不会保留变体分桶范围。将实验分配更改为 0% 后,如果再次将其更改为 50%,云眼 会从头开始为每个用户启动分配流程:云眼 不会保留 40% 设置中的变体分桶范围。
要完全防止变体重新分配,请使用用户配置文件服务实施粘性分桶,该服务使用缓存层将用户 ID 保存到变体分配中。
端到端分桶工作流
下表突出显示了各种用户分桶方法如何相互交互:
| 用户分桶方法 | 在以下之后进行评估: | 在这些之前进行评估: |
|---|---|---|
| 强制变更 | - 不适用 | - 用户允许列表 - 用户配置文件服务 - 受众群体定位 - 互斥组 - 流量分配 |
| 用户许可名单 | - 强制变异 | - 用户配置文件服务 - 受众定位 - 互斥组 - 流量分配 |
| 用户配置文件服务 | - 强制变更 - 用户允许列表 | - 受众定位 - 互斥组 - 流量分配 |
| 互斥组 | - 强制变更 - 用户允许列表 - 用户配置文件服务 - 受众定位 | - 流量分配 |
| 流量分配 | - 强制变更 - 用户允许列表 - 用户配置文件服务 - 受众群体定位 - 互斥组 | -不适用 |
🚧
如果对用户应如何进行分桶存在冲突,则要评估的第一个用户分桶方法将覆盖任何冲突的方法。
让我们了解一下 SDK 如何评估决策。此图表是一个全面的示例,探讨了所有可能的因素,包括特定用户和强制变体等质量检查工具。
- 将执行 Decide 调用,开发工具包开始其分桶过程。
- SDK 可确保标帜规则正在运行。
- 如果用户处于实验规则中,SDK 会将用户 ID 与许可名单进行比较。列表中的特定用户被强制使用变体。
- 如果提供,SDK 将检查用户配置文件服务实现,以确定是否存在此用户 ID 的配置文件。如果是这样,则会立即返回变体并结束评估过程。否则,请继续执行步骤 5。
- SDK 会根据提供的用户属性检查受众条件。如果用户符合纳入目标受众的条件,SDK 将继续进行评估;否则,用户将不再被视为有资格参与实验。
- 哈希函数返回映射到分桶范围的整数值。这些范围基于 云眼 仪表板中设置的流量分配细分,每个范围都对应于特定的变体分配。
- (测试版)如果使用分桶 ID,SDK 将使用实验 ID 对分桶 ID(而不是用户 ID)进行哈希处理,并返回变体。